Expediting the course of AI
Through this blog, the main idea is to take a quick look at Artificial Intelligence. First and foremost, we should understand about Learning. Conceptually, learning is "changing behavior, understanding, or internal structure based on experience". With that being said, the ability to learn is not only possessed by humans, but other animals, and some machines. The core idea is we try new things, we get feedback on the work we do, re-iterate and adjust for better work. So learning is fundamentally an optimization loop.
$$\text{Try something} \rightarrow \text{See result} \rightarrow Adjust \rightarrow Repeat$$
Throughout making this blog, I felt it the concepts are dislocated. So treat each piece individually.
This is important because modern AI systems also learn through repeated adjustment. These adjustments comes from Knowledge, which are information, awareness, or understanding gained through experience or study. It forms the basis of what we know and how we act. It can be categorized into two types: Explicit Knowledge and Implicit Knowledge.
Explicit knowledge is information that can be easily expressed, written down, and shared with others. This is the most basic form of knowledge and is usually documented and readily available. Examples include: Rules, Formulas, Instructions, Databases, Manuals, Books, Contracts, Policies, etc.
Implicit knowledge, on the other hand, involves applying what we know in a practical way. We gain this kind of knowledge through experience, and it's often passed on through social interactions and casual conversations. Examples include: Recognizing faces, Understanding sarcasm, Riding a bicycle, Understanding tone, Tie a shoelace, Drive a car, Read handwriting, etc.
Humans possess massive amounts of implicit knowledge naturally. Machines struggle with this.
Intelligence
Intelligence Intelligence is the ability to learn from experience and adjust to different situations. Involves shaping and choosing our surroundings. Conventional standardized tests show that intelligence, as measured by raw scores, changes throughout a person's life and from one generation to the next. NCBI
A system is more intelligent if it can succeed in many different environments, rather than just being good at one specific task. For instance, stockfish is a really good open source chess engine, it can play chess well, but can't write like a normal person. Humans have the inherited will to handle many different situations. To be adaptable, a system needs to be able to learn from a few examples, deal with new situations, apply what it has learned to new areas, plan ahead, think abstractly, and be aware of emotions and social cues.
Artificial Intelligence
Artificial Intelligence (AI) is a machine's ability to mimic human intelligence, creating systems that work on their own to solve complex problems in ways similar to how humans think. The idea of using computers to mimic human thought and behavior was first described by British mathematician Alan Turing in 1950. He proposed the Turing Test, which would later become a key concept in the field. Pioneers like Charles Babbage, Ada Lovelace, and Turing developed the theoretical foundations for computers and machine intelligence.
It began to take a shape at 1956 at the Dartmouth Conference, where John McCarthy coined the term "artificial intelligence." This marked the beginning of AI as a formal area of research that draws on multiple disciplines.
Some examples of modern AI are as follows:
- Face recognition
- Language understanding
- Playing chess
- Driving cars
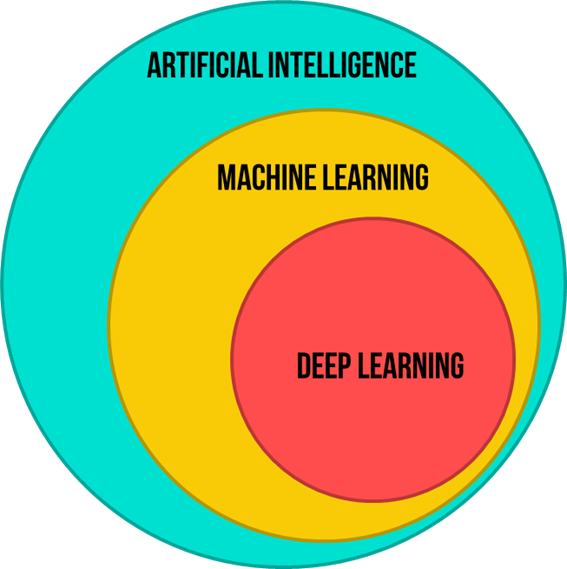
We should understand that Machine learning, Deep learning are different subsets of Artificial Intelligence. In general: $\text{AI}\supseteq \text{ML} \supseteq \text{DL}$. For more refer to this diagram.
{kind=link}
Rule-Based AI
Early AI researchers tried to encode intelligence manually by writing explicit rules. This approach became known as Rule-Based AI or Expert Systems. Rule-based systems use logical if-then statements created by domain experts. For example:
- IF email contains "free money" → THEN mark as spam
- IF temperature > 100°F → THEN flag as fever
Rule-based systems are similar to the human left brain, because it follows logic. These systems comes with it's own limitations. They work well in structured and predictable situations. But many tasks that people do are not like that. They require intuition, depend on the context, and can be unclear. Consider face recognition. It's impossible to come up with rules that cover every situation, like different lighting or people wearing glasses.
The Core Issue
It is not possible to fully express human intelligence as explicit laws. A lot of our abilities, such as identifying faces, deciphering sarcasm, and deciphering idioms, rely more on experience, context, and intuition than on strict reasoning. Because of this constraint, researchers have shifted their focus to machine learning, in which systems learn patterns from data rather than according to manually written rules.
Machine Learning
Machine learning was the second attempt to AI. The core idea was "Let Machines Learn". Invented by Arthur Samuel in 1959, the field experienced early advancements (such as the perceptron), but it was severely constrained by a lack of computing, which caused a delay. Compared to rule based system, here machines were given examples and let them discover patterns themselves.
Early Machine Learning
Systems such as spam filters, Netflix recommendations, and voice recognition services were highly rated. However, it had significant limitations. It couldn't engage in meaningful conversations, understand entire paragraphs, or reason deeply. Now, we can discuss the three major obstacles the field has to face. One was the scarcity of data. To train these massive models requires large amounts of labeled examples, but before the internet was widespread, digital data was limited. The second obstacle was inadequate computing power. Training deep models requires complex mathematical operations, such as matrix multiplication and gradient calculations, which older CPUs couldn't handle efficiently. This meant training could take years instead of days. The third obstacle was the field's immaturity. It required deep human expertise to engineer features, and model architectures were limited. Deep networks had problems with vanishing gradients, and standardized tools were almost non-existent. Due to these constraints, early machine learning was only effective for specific, well-defined tasks and was far from achieving human-level intelligence.
AI Winters
AI has gone through periods of collapse known as AI Winters, where interest towards the field diminished due to no noticeable breakthroughs. The first AI Winter occurred in the 1970s after researchers said human-level AI would arrive soon. But systems did not work as well as expected, and funding disappeared. This downturn happened because, computers were not powerful enough, there was not enough good data, and the algorithms used were too simple to handle the complexity of the real world.
The second AI Winter occurred in the 1980s and 1990s, when expert systems failed to succeed commercially. These systems, which relied on rules, were brittle and only worked under specific conditions. They broke down easily if the rules were not followed, needed constant maintenance, and were costly to build and update. This led to AI falling out of favor, a decrease in funding, the closure of many AI companies, and a sharp drop in research publications.
Why AI Exploded After 2012
Three reasons converged for the growth, $data + compute + algorithm$. With the surge of social media results in heavy data outflow. Labs and researchers were able to scrap the data to make better models. GPU was the next factor, with parallel computing and the efficiency of mathematical operation have given enough scope for this. At last researchers were able to come up with better algorithms that improved the entire pipeline.
Why Language Is Hard Human language is ambiguous and contextual. For example, the sentence "I saw the man with the telescope." is simple for us. A human can answer "Who has the telescope?" observer/man?. Both interpretations are valid. But computers prefer precise logic or ambiguous language. That's a problem, human language is not precise. Our language consist of Ambiguity, meanings that are context-dependent, pragmatics and implicature and the requirement of environment. This is only a surface level of the problem. We have more issues with human language.
Early NLP (Natural Language Processing)
Attempt #1: The Lexical Lexicon and the Polysemy Constraint
The first attempts to decode language using computers involved matching words to set definitions. For instance, a system might store "Apple" with the definition of a type of fruit. But this approach fails when a word has several meanings. "Apple" can refer to a fruit, a technology company, or a music label. Without context, a system cannot tell these meanings apart. This method has its limits because it doesn't take into account that language is always changing, and a word's meaning depends on the text around it, not just the word.
Attempt #2: Stochastic Modeling and the Probability of Sequence
As the limitations of static definitions became clear, the field moved toward Statistical NLP, prioritizing the frequency of word patterns over formal definitions. Systems used probabilistic frameworks like N-gram models, Hidden Markov Models, and Conditional Random Fields to predict word sequences based on historical data. For instance, a statistical model knows that "New" is often followed by "York" because it appears that way in many texts. This approach was used in early versions of Google Translate. But there's an important distinction: recognizing patterns is not the same as understanding them. These systems can predict the next likely sequence of characters or words, but they don't truly comprehend the meaning. They work like advanced calculators, using probability to mimic language structure without being able to think about what it means or create real context.
The Breakthrough: Words as Numbers
The evolution of Natural Language Processing took a significant turn when it moved from discrete symbols to high-dimensional vector space, often referred to as Words as Numbers. We teach computers to understand mathematical representations called embeddings. In this system, a word like "Apple" is no longer just a sequence of characters, but a dense vector like $[0.92, -0.14, 0.05, \dots]$, which maps the word into a multi-dimensional semantic space. This change allows language to be treated as a geometric problem, making it possible for machines to calculate the "distance" between concepts.
Word Embeddings
Modern language modeling relies on word embedding, where each unique word in a vocabulary is assigned a high-dimensional vector. These vectors are not just random numbers, but represent the word's meaning in a dense and distributed way, learned from large datasets. For a word like "Apple," we might think of features like "redness" or "edibility," but the model learns abstract features that capture complex aspects of language, including syntax and semantics, in ways that may not be immediately obvious to humans. By breaking words down into numerical features, we can visualize how a machine categorizes different concepts. Each value in a vector represents the strength of a specific feature.
| Word | Royalty | Gender (M) | Edibility |
|---|---|---|---|
| King | 0.98 | 0.95 | 0.01 |
| Queen | 0.97 | 0.05 | 0.02 |
| Apple | 0.02 | 0.00 | 0.94 |
The key insight of this approach is that meaning is represented geometrically. When words are plotted as points in a high-dimensional space, those with similar meanings or functions are close together. This spatial relationship lets the model recognize synonyms and categories based on distance - for example, "cat" is near "dog," and "car" is near "vehicle."
This "embedding arithmetic" reveals that the model has captured the underlying structure of language:
- Gender: $\text{King} - \text{Man} + \text{Woman} \approx \text{Queen}$
- Geography: $\text{Paris} - \text{France} + \text{Italy} \approx \text{Rome}$
- Verb Tense: $\text{Walking} - \text{Walk} + \text{Swim} \approx \text{Swimming}$
Limitation of Basic Embeddings
Standard embedding models have a major limitation: they can't handle words with multiple meanings. In these models, each word is assigned a single, fixed vector, no matter how it's used. This causes problems with words like bank, which can refer to a financial institution or the side of a river. Because the vector is fixed, the model can't distinguish between these different meanings, so it ends up with a vague representation that doesn't capture the specific meaning of a sentence.
To humans, these are clearly different concepts, but to a basic embedding system, bank has the same meaning in every context. This problem led to the development of contextual embeddings, introduced by models like ELMo, BERT, and GPT. These newer systems represent words in a more dynamic way. Instead of assigning a fixed vector to each word, they generate the vector based on the surrounding words. This allows the model to adjust its representation of a word in real-time. By taking context into account, these models can represent bank differently in different sentences - as a "finance" concept in one sentence and a "nature" concept in another. This helps to close the gap between the rigid math used in computer models and the flexible way humans use language.
Sequence Models (RNNs)
Recurrent Neural Networks (RNNs) were the first architecture designed to model language's temporal nature. They process tokens one by one and keep a hidden state that stores information from previous tokens. When a new token arrives, the network updates this hidden state, gradually building a representation of the sentence. For example, it processes the words in a sentence in order, such as "I", then "went", then "to", and so on.
Variants have improved memory control. Basic RNNs are simple but tend to forget. Long Short-Term Memory (LSTM) cells have input, forget, and output gates that help preserve important signals over longer periods. Gated Recurrent Units (GRUs) are a simpler version of LSTMs that reduce computation without sacrificing much performance. Bidirectional RNNs process sequences in both directions, which allows them to capture the full context.
The sequential design of RNNs creates a bottleneck for long-range dependencies. Since information has to flow one step at a time, tokens that are far apart can become diluted or lost. Training RNNs also has its problems - errors that are backpropagated shrink rapidly, while others grow out of control. The fixed-size hidden state can only hold so much information, which further limits the effectiveness of RNNs on long texts. This led to a move toward parallel, non-sequential architectures.
Transformer (2017)
In 2017, a few Google engineers considered simplifying models by using attention. The paper "Attention Is All You Need" introduced a non-sequential architecture that processes entire sequences at once, replacing the traditional sequential RNN-based approach. Transformers use self-attention, allowing each token to interact directly with every other token. This gives models direct access to long-range context and enables them to process information in parallel on GPUs.
The concept of self-attention involves calculating weighted interactions between tokens, so the model can focus on the most relevant words, regardless of their distance. This helps resolve issues like pronoun reference and long-range dependencies by assigning high attention weights to the correct antecedents. For example, the model can link "it" to "animal" or "street" depending on the context.
With improved parallel computing, training larger models become feasible resolving the forgetting issues at working scale. The Transformer model also introduced multi-head attention, which helps create contextual embeddings.
Transformers are now the basis for modern large language models, such as the GPT family, Claude, and Gemini, driving progress in scale, performance, and versatility in NLP and other areas.
How ChatGPT Works
A production conversational agent like ChatGPT is built from three main components: Transformer architecture, massive internet-scale data, and auto-regressive prediction. This involves combining large, diverse text collections with a Transformer to predict the next token, creating a foundation model.
The model is trained on massive, varied sources from the internet, including books, papers, forums, code, and websites. This exposure to a wide range of language and facts helps the model learn. The primary goal of training is to predict the next token in a sequence. For example, given the context "$\text{The quick brown ...}$", the model evaluates possible completions and chooses the most likely one. Some models, like BERT, use a variation called masked language modeling. After initial training, the models are fine-tuned through instruction and reinforcement learning to make them more helpful and behave like conversational assistants.
Why Next-Word Prediction Creates Intelligence
Predicting the next word is a straightforward task, but training a large model on a vast and diverse range of texts makes it learn a lot about language and how it works. To make accurate predictions across different topics, the model has to understand grammar, meaning, facts, and how people reason. This helps the model develop its own internal understanding of language and the world.
Text Generation Loop
It's a auto-regressive loop where the model's output at time-step $t$ becomes part of its input for time-step $t+1$.
- Step 1: Input:
The$\rightarrow$ Predicts:quick - Step 2: Input:
The quick$\rightarrow$ Predicts:brown - Step 3: Input:
The quick brown$\rightarrow$ Predicts:fox
Emergence: The Law of Scaling
Quantitatively, as data, models, and computing power increase, we need to consider the scale. Even developers struggle to understand the uniform distribution of large language models due to their size. As models expand, they develop complex behaviors that are not present in smaller models, once a certain scale threshold is reached. These behaviors include chain-of-thought reasoning, tool use, planning, meta-learning, and self-consistency.
We can see a shift from task-specific models to more general models. The focus is now on systems that can handle multiple forms of input, think and reason about their own behavior, and act as agents that can use tools.
The Core Intuition: We have moved from AI that knows things (Knowledge) to AI that can reason through things (Logic) and finally to AI that can do things (Action).